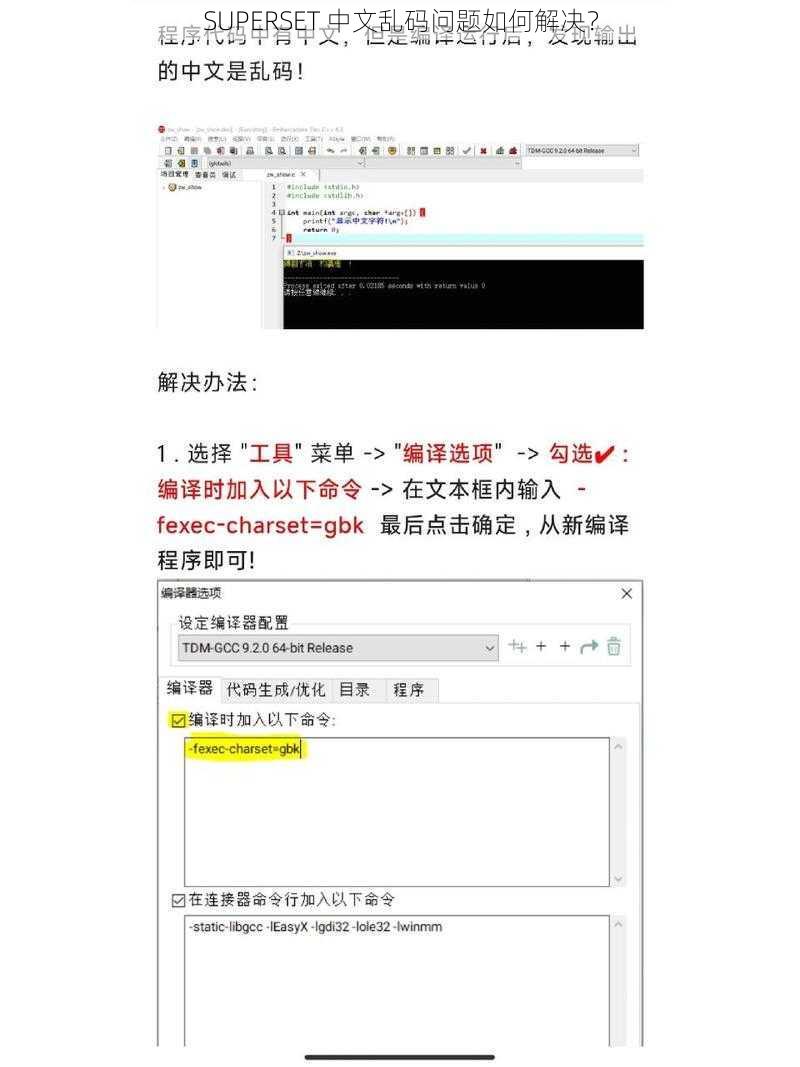
SUPERSET 中文乱码问题如何解决?
在数据分析和可视化领域,SUPERSET 是一款强大的工具。有时在处理中文数据时,可能会遇到中文乱码的问题。这个问题可能会导致数据无法正确显示,给工作带来困扰。 SUPERSET 中文乱码问题的解决方法,帮助你顺利解决这一难题。
1. 选择合适的编码格式
在使用 SUPERSET 时,确保数据源和数据文件的编码格式与 SUPERSET 的设置相匹配。常见的编码格式包括 UTF-8、GBK 等。你可以通过查看数据源的文件属性或在代码中指定合适的编码来解决乱码问题。
2. 设置正确的字符集
在 SUPERSET 的配置文件或代码中,设置正确的字符集。字符集的设置将影响数据的显示和处理。确保将字符集设置为支持中文的字符集,如 UTF-8。
3. 处理特殊字符
某些中文字符可能包含特殊的编码或格式。在处理这些字符时,需要使用适当的方法进行转义或编码。例如,对于中文字符串,可以使用转义序列或编码方式来正确显示在 SUPERSET 中。
4. 检查数据源
确保数据源本身没有中文乱码问题。检查数据源的文件是否损坏或编码错误。如果数据源存在问题,可能需要修复或重新获取数据。
5. 使用数据预处理
在将数据加载到 SUPERSET 之前,可以使用数据预处理工具或库来处理中文数据。这些工具可以进行编码转换、清理和规范化,以确保数据的正确性和可读性。
6. 参考官方文档和社区资源
SUPERSET 官方文档提供了关于中文支持和乱码处理的详细信息。社区论坛和资源也是解决问题的好去处。与其他用户交流经验,参考他们的解决方案,可能会给你带来新的思路。
7. 调试和打印输出
在处理中文乱码问题时,可以添加调试代码来打印输出数据的编码和显示结果。通过观察打印信息,可以确定问题的根源并找到相应的解决方法。
8. 尝试不同的 SUPERSET 版本
有时候,中文乱码问题可能与特定的 SUPERSET 版本有关。尝试使用不同版本的 SUPERSET,看是否能够解决问题。
9. 寻求专业帮助
如果以上方法都无法解决中文乱码问题,你可以寻求专业的技术支持或咨询相关领域的专家。他们可能具有更深入的知识和经验,能够提供针对性的解决方案。
解决 SUPERSET 中文乱码问题需要综合考虑多个因素,并采取适当的方法。通过选择合适的编码格式、设置字符集、处理特殊字符、检查数据源等步骤,你可以提高数据的可读性和显示效果。参考官方文档、社区资源和寻求专业帮助也是解决问题的重要途径。
希望提供的方法能够帮助你顺利解决 SUPERSET 中文乱码问题,让你在数据分析和可视化中更加高效和便捷地处理中文数据。